其实数据分析最应该做的,反而是那些现实中间时不时出现,但是人的经验又做不好,又特别期望数据能帮忙的一些场景。
这要求我们在数据处理上,即使有些情况基于现在的模型和数据支撑不了,也要预想到这些情况,至少知道这项技术的适用范围是什么,而不是做了一个在特定情况下特别好的东西,就推而广之。
任何模型都是物理设计的一个简化,都不可能脱离于物理世界,现在讲数字孪生体,也要看模型用于研发阶段还是在运维阶段,毕竟不可能有一个模型百分之百的等于物理世界。
在现实中说抓基本面,基本面是什么?比如做大宗物资的需求预测,就要梳理大宗物资供和需,它的驱动因素到底是什么?不用特别定量,先大概把关联因素梳理完。比如做设备的运行优化、故障监测,不要一上来就用各种复杂的公式,其实更应该了解基本量之间的影响关系、动员关系。
5、闪烁其词:在“科学”名义下,以“非科学”的态度去做“科学”的事情。
做工业数据分析,我们需要知道一个模型的使用边界,没有一个模型能解决所有问题,或者适用于所有情况,除非他是一个伪科学。
做数据分析6个阶段,真正耗时的是什么?是最早的业务问题理解,这也是最关键的阶段。当然CRISP-DM默认把社会分工做好了,假设数据分析师只做数据挖掘,数据分析,在现实中间不可能这么理想,有可能别人给你理出来的问题不一定正确,在某种程度上要重新定义问题,而不只是理解。
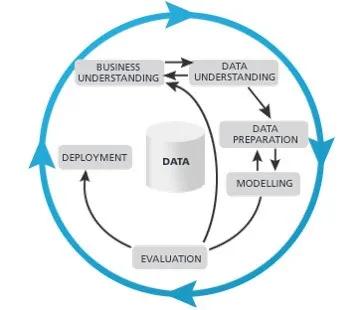
当然还有一些跨专业要理解,不熟悉的领域的背景知识都非常重要,做化工连化工原理都不知道,做电力连电力的基本动力学都不知道,去盲做就很容易挖出来一些常识,这是社会资源的一种浪费。
第二比较耗时的是数据准备,正常情况下数据挖掘非常好做,但很多时候,数据挖掘偏偏是处理那些看起来不太正常,但在现实中间经常出现的一些状况。作为一个严谨的数据分析师,我们要从数据中间,看到好多业务专家早期没有想到的一些信号,甚至是他认为不可能在数据中出现,或是他习空见惯,没意识到,没给介绍的一些情况,这些有时候会大大影响分析模型的准确度。要自动执行的时候,可用性是非常重要的。
数据只是一种表象,作为数据分析师,我们的态度是相信数据,但是不迷信数据,因为数据本身的采集方式可能会有偏差,比方以前讲的幸存者偏差,只有没被打掉的飞机才飞回来了,所以我们损失了很多,薄弱环节被打掉的一些信息。
有些数据的采集方式、采集精度,包括数据的样本选择上,可能会给我们误导,看起来做的不错,其实本身数据没有反映物理现实。包括传感器的安装位置,传感器本身的测量原理,可能会给数据本身带来一定的影响,这时候需要比较谨慎和乐观的态度去挖掘,同时要像其他工科一样反复推敲,这是非常纠结和磨难的一个过程。






