
本文作者:昆仑数据首席数据科学家 田春华
数据分析过去在工业应用中取得了的一些成绩,也有很多不如意的地方,今天分享在实际过程中有哪些常见的误区,由于时间问题,今天只讲7个技术方面,后边有时间再给大家细细聊。
7个误区,分三批,包括规划层面,技术路线方面,以及执行层面,可能遇到的问题。
1、言不及义:脱离业务逻辑的数据分析是浪费。
曾和合作伙伴探索过空压机的大数据分析。在涉及到工业设备的大数据分析应用中,有很多PHM的案例。但在跳到智能运维之前,最好先讨论一下预期的业务逻辑,我们的目标是做第三方运维业务(大数据用来提高维修效率),还是通过空压机的数据,来支撑一种新的业务模式,比如供应链金融、业务流程优化、能效优化等。
首先剖析一下,先不考虑现实条件,假设技术是百分之百的成功,这个技术实现之后,到底能干嘛?
一年的这种压缩机,它的运维成本到底是多少?如果我是这个设备制造商,我做智能运维到底是来帮谁实现什么?我的收入或者我的成本来自于什么地方?
如果智能运维的收入包括利润率都非常低,整个产业链,整个行业都还没有发力,不妨转变业务逻辑,不要急于模仿一些看似别人在其他领域已经成熟的案例,先灵魂拷问自己的商业本质是否合理。

2、指雁为羹:脱离约束条件的“乌托邦”很难成功。
案例:这类问题通常出现在一些调度优化、运筹优化层面,一讲生产调度或者运筹优化,大家很容易的就想做全局优化,这是大家的梦想,只有全局优化才能有提升的空间。但是现实中,要具体问题具体分析,不能脱离物理世界的约束条件。
例如港口的集装箱码头,其中一个很重要的问题就是码头的堆场优化。因为堆场决定容量,香港的码头是比较拥挤的,做对比优化的空间很大,效益也大,我们要分析船来了之后怎么快速的支持装货、卸货。
但是做堆场优化,业务范围到底做多大?客户希望做端到端的堆场优化,一个集装箱来了,就要决定最优位置。这里忽略了,为了做堆场优化,首先要有比较明确的集装箱的到达量预测,预测必须相对准确;第二,我要整个装备的维修周期数据,要获得排班数据,要获得船期数据等各种关联数据;第三,要避免场内卡车的拥堵,如果同一艘船的所有集装箱都放在一起,装船时候可能会造成局部拥堵。
现实情况下你很难获得这么全的数据,中间的约束很多,首先,流量预测就很难做的精准。第二,船的到达,按说有固定的周期,但是也有些天气因素,有些如当前疫情因素是不完全可控的。在这种情况下,如果做优化,是基于大量的假设,效果可能会打一些折扣。
不光在码头,其实工厂内的调度优化也是这样,我们虽然追求全局优化,但还是要考虑现实的条件,哪些数据不可得,包括得到之后他节省的成本到底有多高,都要认真考虑,当然技术上肯定会尽最大的努力来做。
3、空中楼阁:与组织形态失配的数据分析很难落地。
过去我们也做过一些,从技术上可行,甚至精度还不错,例如在设备故障诊断里一些重大部件的故障预测,虽然样本比较少,结合一些机理和数据挖掘知识,有的时候还可以做出来一个不错的结果。但是结果落地的时候,其实大家很沮丧,问题就在于我就发现一个问题,有的时候预示着在现有的考核体系下,可能会某种程度上暗示着现有的运维团队做的不到位,过去的定期维护做的不太好。这时候要指望现场一线团队给出真实的或者及时的反馈,通常很难。
大家可以联想一下,包括质量提升等各种课题都会遇到类似的问题,在工业以外,甚至在商业里的很多预测,推行的时候也会遇到类似的问题,这个课题正好是某个部门负责的,他天天用自己经验来做,现在你用数据分析比以前更好,除非这个项目从归口,从组织形态上做一定的调整,否则通常很难让他真正用起来。
4、避实就虚:追 “时髦”,讲“套路”,忘记了本来可行的做法。
例如院线的票房预测,上映之前的预测,会决定排片到底当时排多少场,排什么时间段,到底做什么样的排片策略?
当时Google发了一篇论文,说通过Google搜索量可以准确预测一个影片的票房,这是一篇引用度蛮高的论文,当时国内好多人非常兴奋,但把这样的方式应用到国内,发现精度并不理想。其实我们是半信半疑的,一个影片票房的基本面是什么决定的?
例如,电影类型与地区的匹配度,它是恐怖片还是什么片?院线里面不同的影院,比方有的是生活区的有CBD的;比方成都喜欢看古墓片,比方广州喜欢看粤语片,上海喜欢看小资片,比方哈尔滨基本上一般是抗战片、武打片比较好,不同地域的人的喜好,是不是都反映在搜索量上?除了题材之外,还有演员的活跃度,在社交媒体的活跃度,导演最近获过什么奖?包括题材是个什么片?后来我们加入了很多,比如地理信息,包括一些过去不同院线之间的销售趋势,包括在什么社交媒体上看演员之间的影响力的增长趋势,以及导演、演员和演员之间谁和谁搭配比较好。
我们当然希望用最简单的方式,就能预测票房、备品备件需求,但还是要多问问本质问题,基本面要考虑全一点。有时候不是难在预测上,而是要考虑一些外部的人为和不可控的影响,包括宏观经济的变化。
其实数据分析最应该做的,反而是那些现实中间时不时出现,但是人的经验又做不好,又特别期望数据能帮忙的一些场景。
这要求我们在数据处理上,即使有些情况基于现在的模型和数据支撑不了,也要预想到这些情况,至少知道这项技术的适用范围是什么,而不是做了一个在特定情况下特别好的东西,就推而广之。
任何模型都是物理设计的一个简化,都不可能脱离于物理世界,现在讲数字孪生体,也要看模型用于研发阶段还是在运维阶段,毕竟不可能有一个模型百分之百的等于物理世界。
在现实中说抓基本面,基本面是什么?比如做大宗物资的需求预测,就要梳理大宗物资供和需,它的驱动因素到底是什么?不用特别定量,先大概把关联因素梳理完。比如做设备的运行优化、故障监测,不要一上来就用各种复杂的公式,其实更应该了解基本量之间的影响关系、动员关系。
5、闪烁其词:在“科学”名义下,以“非科学”的态度去做“科学”的事情。
做工业数据分析,我们需要知道一个模型的使用边界,没有一个模型能解决所有问题,或者适用于所有情况,除非他是一个伪科学。
做数据分析6个阶段,真正耗时的是什么?是最早的业务问题理解,这也是最关键的阶段。当然CRISP-DM默认把社会分工做好了,假设数据分析师只做数据挖掘,数据分析,在现实中间不可能这么理想,有可能别人给你理出来的问题不一定正确,在某种程度上要重新定义问题,而不只是理解。
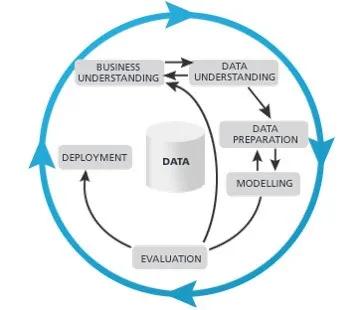
当然还有一些跨专业要理解,不熟悉的领域的背景知识都非常重要,做化工连化工原理都不知道,做电力连电力的基本动力学都不知道,去盲做就很容易挖出来一些常识,这是社会资源的一种浪费。
第二比较耗时的是数据准备,正常情况下数据挖掘非常好做,但很多时候,数据挖掘偏偏是处理那些看起来不太正常,但在现实中间经常出现的一些状况。作为一个严谨的数据分析师,我们要从数据中间,看到好多业务专家早期没有想到的一些信号,甚至是他认为不可能在数据中出现,或是他习空见惯,没意识到,没给介绍的一些情况,这些有时候会大大影响分析模型的准确度。要自动执行的时候,可用性是非常重要的。
数据只是一种表象,作为数据分析师,我们的态度是相信数据,但是不迷信数据,因为数据本身的采集方式可能会有偏差,比方以前讲的幸存者偏差,只有没被打掉的飞机才飞回来了,所以我们损失了很多,薄弱环节被打掉的一些信息。
有些数据的采集方式、采集精度,包括数据的样本选择上,可能会给我们误导,看起来做的不错,其实本身数据没有反映物理现实。包括传感器的安装位置,传感器本身的测量原理,可能会给数据本身带来一定的影响,这时候需要比较谨慎和乐观的态度去挖掘,同时要像其他工科一样反复推敲,这是非常纠结和磨难的一个过程。
从某种程度上,数据分析的整个过程,和传统的工科工程化方法是一样的。任何东西都是基于一定的假设所做出来,放到一个现实中,或者相对客观的现实中去验证,验证完之后,反复的去观察,这样才有可能从一定规律上反映了这个物理现实。
什么叫科学的态度,就是要反复问,任何东西都是可以被证伪或证实的,没有什么东西是绝对对或者绝对错的。
6、舍本从末:把一个简单的问题复杂化
数据分析师,有时候经意不经意地把一个问题给复杂化了,有时候有些工艺机理非常简单,基本面就在那,没必要把这个问题拔到一个深度学习或者一个什么高深的方法来做。
该简单的问题就简单处理,不要在不重要的地方花太多时间,好多数据分析师都是比较较真的,像我早期也是,细枝末节没搞清楚,心里就不舒服。数据分析作为一个工程化方法,要抓大放小,在一定的时间、空间、时间、费用的约束下,做到最好。
我以前学控制的,到大四的时候,接到一个实际卫星的姿态控制项目,上来我们就列状态方程传递函数,因为卫星模型也比较成熟,先证明稳定性,再通过根轨迹或者是波特图设计做控制系统的设计。我自己当时非常得意,因为上学上了十几年,第1次看到自己学了这么多年的东西,终于在现实中间有点用了。
我们去跟航天的专家交流,对方给的评价也比较高,当时我问,你们做卫星设计的时候,怎么做?他说,其实没有你考虑那么复杂,把不重要的全忽略掉,卫星三个轴都是耦合的,你不妨假设三个轴是解耦的,剩下的你就把它想象成一个刚体,到底偏了几度,你到底多少分钟想把它转回来?你能加多大的力?加多大力,电流马上就转换成控制参数。星箭分离之后,到底喷气怎么喷?你想加多大的冲量,一个冲量喷一下持续多少秒,然后产生多大冲量,冲量产生多大加速度,我要多少秒纠正过来?基本面就这么多,就这么简单。
当时对我触动蛮大的,不要一上来就把一些不重要的复杂因素都考虑进去,这个观念一路影响我后面的研究与分析。当然任何简化都是有前提的,在卫星仿真里面,这种简化是在小角度或者接近稳定的情况下使用,如果大部件分离或者太阳能翻板刚打开等大动态的情况下,简化是非常危险的。

再举个例子,风力发电机叶片结冰,可以做成结冰检测,在结冰严重,PLC警报之前,早期检测出来;也可以做结冰预测,但这两个问题难度差是十万八千里。结冰预测的前提,首先要做天气预报。大家也都知道宏观天气预报,气象局努力了这么多年,也上了很多手段,在有些地方有时候还是预测不准。且不说我们要做局部天气预报,每个风机每个截面都要做,还要做到以小时计,这非常难的,这是一个世界难题,非常难做。
我们有时候有意无意的把一个问题复杂化,做结冰检测,其实就看风机的运行状态,就看它的出力和风速的关系,有没有一个持续的缓慢的下降,或者再综合其他的故障信息,就能把一个问题简化不少。
7、因陋就简:数据基础不健全,就轻易放弃
是不是数据基础不好,我就不要做大数据?对数据分析师来说,数据质量从来没好过。
我也接触过商业的数据,银行的数据,电信的数据稍微偏好一点,但是对我们数据分析师那种孜孜不倦的要求来讲,数据质量从来没好过,我是深有体会。
以前在境外做过一个城市管网的失效预测,预测一个地下水管网,明年哪个管子可能会坏?从数据的质量讲,客户非常自信,因为他的信息化水平大概领先于国内十多年。我需要最基本的管网的管件、管材管理,所处位置,地面的交通数据、环境数据,包括附近有什么建筑物,他的土地利用性质,还需要天气数据……他说这都有,一个地方政府能把每条道路的交通流量,每个地方土地使用性质附近有什么建筑物,包括最近有没有下雨,甚至整个管网的压力区,平均水压是多少都能给出来。
如果单个看,每种数据缺失都不太严重,数据完整度能到80%。但是一旦把这些因素关联起来,要建模型的时候,我要把管网本身的特性、土地使用性质、天气信息、土壤的酸碱度信息等综合来预测,这时候一一关联起来就发现,真的有完整数据的管道,不到30%。
这其实让客户非常震惊,数据集相互孤立着,有些字段偶尔缺一点也不明显,但是对数据分析来说,我要关联起来看,要横着看竖着看,所以我对数据质量的要求非常高。
从我们数据分析来看,其实数据基础健不健全都是相对的,有些数据分析发现的数据缺失,也是帮助信息化建设来把它不断的补全的一个过程。有什么样的数据做什么样事,哪怕数据不全,也可以从简单的做,从容易的做,从基础比较好的地方做。
任何一个正常的科学技术都是有边界的,工业大数据作为一个技术,肯定有适用和不适用的范围。
如果大家在现实中遇到什么场景,昆仑数据的数据分析师愿意和大家一起探讨,看看这个问题应该怎么定义,用数据能不能解,欢迎大家和我们互动。




